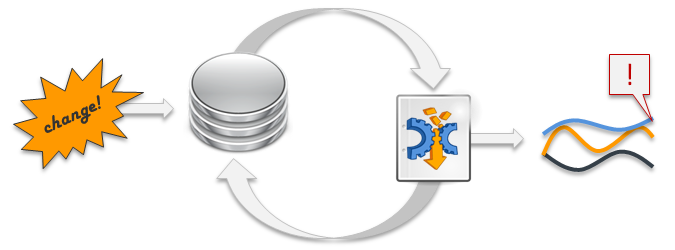
DataCleaner er et open source og helt gratis løsning for organisationer og virksomheder, der ønsker at øge og måle kvaliteten af deres data.
Med DataCleaner, vil brugere være i stand til at profilere, sammenligne, validere data mod forretningsregler, og overvåge udviklingen af disse målinger over tid.
Blandt dens funktioner kan nævnes dataovervågning, data profilering og DQ-analyse, data rengøring og berigelse, opdage og flette dubletter, kundedata kvalitet, samt superhurtig ETLightweight (Extract-Transform-Load).
Hvis du vil vide mere om DataCleaner funktioner og kapaciteter, samt hvordan man arbejder med det, henvises til http://eobjects.dk/docs
What er nyt i denne udgivelse:
- Forbedringer og nye funktioner:
- Vi har gjort det muligt at skabe og droppe tabeller via skrivebordet UI af DataCleaner. Bemærk, at udtrykket & quot; bord & quot; her faktisk dækker mere end blot relationsdatabasetabeller. Det omfatter også Ark i MS Excel datastores, Samlinger i MongoDB, Dokumenttyper i CouchDB og ElasticSearch og så videre ... Dybest set alle datalagerenheder typer, der understøtter skrive-operationer, undtagen single-table datastores som CSV datastores, understøtter denne funktionalitet! Funktionaliteten er eksponeret via:
- & quot; Opret bord & quot; aktiveret via højreklik-menu af skemaer i træet på venstre side af ansøgningen.
- & quot; Opret bord & quot; aktiveret også via table-udvalg input i komponenter såsom Indsæt i tabellen, tabel opslag og opdatering bord.
- & quot; Drop bord & quot; aktiveret via højreklik-menu af tabeller i træet på venstre side af ansøgningen.
- Vi har tilføjet den (valgfrit) evne til at angive din Salesforce.com webservice Endpoint URL. Dette giver dig mulighed for at bruge DataCleaner at oprette forbindelse til sandkasse miljøer i Salesforce.com samt til dine egne endpoints.
- ElasticSearch er blevet forbedret, så brugerdefinerede tilknytninger samt genbruge de ElasticSearch datalagerenheder definitioner nu også til at søge og indeksering.
- prøvetagning af optegnelser og udvælgelse af potentielle dubletter i Duplicate afsløring funktionen er blevet forbedret, hvilket fører til hurtigere konfiguration, fordi de beslutninger, der træffes under træningen er mere repræsentative.
- Duplicate afsløring model filformatet er blevet opdateret som har fjernet behovet for en separat "henvisning" fil for at redde tidligere uddannelse beslutninger. Kompatibilitet med det gamle format er bevaret, men ved hjælp af det nye format tilføjer mange fordele for brugeroplevelsen.
- Fejlrettelser:
- En tråd sult problem blev rettet i DataCleaner skærm. Virkningen af dette spørgsmål var stor, men det skete kun i sjældne og meget tilpassede tilfælde. Hvis brugerdefinerede lytteren objekter på DataCleaner monitor ville kaste en fejl, ville det resultere i en ressource aldrig blive frigjort og optage en tråd fra Quartz-planlægning pulje på serveren. Hvis dette ville ske mange gange serveren kan i sidste ende løber tør for tråde i denne pulje.
- Den lodrette menu på resultatet skærmen er nu gør et ordentligt stykke arbejde med at vise etiketterne på de komponenter, der har resultater. Det gør det lettere at genkende hvilke menupunkt peger på hvilket resultat element.
Hvad er nyt i version 3.5.5:
- Den "Synonym opslag 'transformation har nu en mulighed at kigge op hver token af input. Dette er nyttigt, hvis du laver udskiftning af synonymer inden værdierne af en lang tekst felt.
- Blokering udførelse af DataCleaner job gennem skærmens webservice for dette kunne nogle gange mislykkes med en bug forårsaget af blokering tråd. Dette problem er blevet løst.
- En forbedring blev lavet i den måde job og rækkefølgen af komponenter er lukket / ryddet op efter udførelse.
- JNLP / Java WebStart version af DataCleaner blev afsløret ved en fejl i Java Runtime forårsager visse JAR-filer ikke skal anerkendes af WebStart løfteraket, under visse omstændigheder. Dette problem er blevet løst ved at gøre mindre ændringer til disse JAR-filer.
- Et par døde links i dokumentationen blev fastsat.
Hvad er nyt i version 3.5.4:
- Det er nu muligt at skjule output kolonner af transformationer . Hiding vil ikke påvirke behandlingen flow på alle, men blot skjule dem fra brugergrænsefladen, og dermed potentielt gøre oplevelsen mere ren, når interagere med andre komponenter.
- En ny web service er blevet tilføjet til overvågning web applikation, som giver en måde at polle status for udførelse af et bestemt job.
- En fejl blev rettet, hvilket får HTML-rapport til at mislykkes for visse analyser typer, når ingen optegnelser var blevet behandlet.
- Og 6 andre mindre fejl er blevet rettet.
Hvad er nyt i version 3.5.1:
- Capture ændret optegnelser:
- et nyt filter blev tilsat for at muliggøre trinvis behandling af poster, der ikke er blevet behandlet før, f.eks til profilering eller kopiering kun ændret poster. De nye filtre navn er Capture ændret optegnelser, med henvisning til begrebet capture Skift data.
- I kø udførelse af jobs:
- DataCleaner skærm vil nu kø udførelsen af det samme job, hvis den udløses flere gange. Dette sikrer, at du ikke ved et uheld køre det samme arbejde samtidigt hvilket kan føre til alle mulige spørgsmål, afhængigt af hvad jobbet gør.
- Mindre fejlrettelser:
- Flere fejlrettelser blev gennemført.
Hvad er nyt i version 3.5:
- Flere guider er nu tilgængelige for registrering datastores; herunder fil-upload til serveren for CSV filer, database forbindelse indrejse, guidede registrering af Salesforce.com legitimationsoplysninger og mere.
- De job bygning troldmænd er også blevet udvidet med flere forbedrede funktioner; Udvælgelse af værdi distribution og mønster finde felter i Quick analyse guiden, en helt ny guide til at oprette EasyDQ baseret kunde udrensning job og et nyt job guiden til fyring Pentaho data Integration job (læs mere nedenfor).
- Du kan nu ad hoc forespørge enhver datalager direkte i web-brugergrænsefladen. Dette gør det nemt at få hurtige eller sporadiske indsigt i de data, uden at oprette job eller andre styrede tilgange til behandlingen af data.
- Når job eller datastores skabes, føres brugeren til at gribe ind med det nybyggede objekt. For eksempel, kan du meget hurtigt køre et job lige efter det er bygget, eller forespørge et datalager, efter den er registreret.
- Administratorer kan nu direkte uploade jobs til lageret, hvilket er særligt praktisk, hvis du ønsker at hånd-redigere XML-indholdet af jobbet filer.
- En masse af den tekniske cruft er nu gemt væk til fordel for at vise enkle dialoger. For eksempel, når et job udløses en stor belastning indikator vises, og når du er færdig resultatet vil blive vist. Den avancerede logning skærm, der er tidligere der kan stadig blive vist på at klikke på et link for yderligere oplysninger.
Hvad er nyt i version 3.1.2:
- Vi har tilføjet en web service i overvågningen ansøgning om at få en (liste over) metriske værdier. Dette gør overvågningen endnu mere brugbar som et centralt infrastruktur komponent, som en måde at overvåge data (kvalitet) og udsætte resultaterne til tredjeparts applikationer.
- Den "Table opslag 'komponent er blevet forbedret ved at tilføje slutte semantik som en konfigurerbar ejendom. Brug af slutte semantik du kan justere, hvis du ønsker at opslag for at arbejde semantisk som en LEFT JOIN eller en INNER JOIN.
- De EasyDQ komponenter er blevet opgraderet, tilføjer yderligere konfigurationsindstillinger og et rigere deduplikering resultat interface.
- ydeevne forbedringer har været et særligt fokus for denne udgivelse. Der er sket forbedringer i motoren af DataCleaner til yderligere at udnytte en streaming behandling tilgang i visse tilfælde hjørne som ikke var omfattet tidligere.
Hvad er nyt i version 3.1.1:
- Dato og tid relaterede analysemuligheder er blevet udvidet , tilføjer distributionsomkostninger analysatorer for ugenumre, måneder og år. Alle analysatorer relateret til dato og tid er nu samlet i en undermenu kaldet & quot; Dato og tid & quot; under & quot; Analyser & quot;.
- En valgfri & quot; beskrivende statistik & quot; mulighed er blevet tilføjet til nummer analysator og dato / tid analysator. Denne indstilling tilføjer yderligere målinger til resultaterne af disse analysatorer, såsom Median, Skewness, percentiler og kurtosis. Disse målinger er valgfri, da deres hukommelse footprint er noget større end de eksisterende målinger.
- Linjerne på tidslinjen diagrammer af overvågningen webapplikation nu har små prikker i dem. Dette er især nyttigt for diagrammer med få (eller endda kun én) observationer i dem -. At påpege præcis, hvor de observationspunkter er
- Forespørgslen parser når påberåber ad hoc-forespørgsler er også blevet væsentligt forbedret. Nu forespørgsler kan indeholde FORSKELLIGE klausuler, * -wildcards, underforespørgsler og er fejltolerant mod tekst-case spørgsmål.
- To nye transformatorer er blevet tilføjet til generering UUID'er og til generering af tidsstempler.
Hvad er nyt i version 3.1:
- Metriske formler - uddybet Data Quality KPI'er:
- Det er nu muligt at bygge meget mere uddybe Data Quality KPI'er i DataCleaner overvågning webapplikation. Brugerfladen gør det muligt at bygge komplekse formler i et regneark-lignende formel stil; ved at bruge variabler indsamlet af DataCleaner arbejdspladser.
- Metriske formler kan kombinere et vilkårligt antal målinger, konstanter og operationer, så længe det kan udtrykkes i en matematisk ligning.
- For eksempel - måle hastigheden af dubletter i procent af den samlede rekord tæller. Eller måle mængden af produktkoder, der er i overensstemmelse med et sæt af flere string mønstre.
- Ad hoc forespørgsler - enhver datalager:
- Med DataCleaner 3.1 du nu kan udføre ad hoc-forespørgsler til enhver datalager! Forespørgsler kan udtrykkes i almindelig SQL og vil blive anvendt til databaser samt filer, NoSQL databaser og mere, hvilket giver en virkelig nyttige forespørgsel mekanisme til at strække sig ind i din opdagelse og data profilering oplevelse.
- Forespørgslen mulighed er også tilgængelig via en web service til at overvåge brugere med ADMIN rolle. Forespørgslen er tilvejebragt som en HTTP parameter eller POST krop, og resultatet er angivet som XHTML bord.
- Value matcher - en ny analyse mulighed:
- Ofte gange du har en fast idé om, hvilke værdier bør være tilladt og forventet for et bestemt område. I DataCleaner der har altid været Value Distribution analysen mulighed, som ville hjælpe dig hævde dine antagelser. I DataCleaner 3.1 selv, har du en mere præcis udbud - Value matcher. Denne analyse gør det muligt at angive et sæt forventede værdier og derefter udføre en værdi fordeling som analyse, specielt til at validere og identificere uventede værdier.
- Kopiering, sletning og styring af jobs:
- Forvaltning af arbejdspladser og resultater i DataCleaner monitor ansøgningen er blevet forbedret betydeligt. Du kan nu klikke på et job i Planlægning side af skærmen, og find management muligheder for operationer såsom omdøbning, kopiering, sletning og mere. Hver operation respekterer forbindelserne til andre artefakter i skærmen, såsom analyseresultater, tidsplaner og mere. Det betyder, at ledelsen af overvågningen repository er blevet meget nemmere og moden.
- Administrer datakvaliteten historie:
- Nogle gange du står situationer, hvor du rent faktisk ønsker at gøre overvågningen med historiske data! Det kan være, at du har historiske lossepladser eller sikkerhedskopiering af databaser, som du ønsker at vise og fortælle historien om. Du kan nu gøre analysen af dette historiske data, uploade den til DataCleaner monitor, og ved hjælp af en ny webservice, sætte en historisk data for den pågældende analyseresultat. Det betyder, at dine tidslinjer ordentligt vil plotte resultaterne ved hjælp af deres tilsigtede dato, men med de resultater, du har indsamlet måske på et senere tidspunkt.
- Grupperet scheduler support (kun EE):
- Planlæggeren af DataCleaner monitor er blevet eksternaliseres, så den kan udskiftes ved hjælp af enkel konfiguration. I Enterprise Edition (EE) i DataCleaner, giver vi et cluster scheduler, giver mulighed for at indlæse balance og distribuere dine henrettelser på tværs af en klynge af maskiner.
- Single-sign-on (SSO) ved hjælp af CAS (EE kun):
- I Enterprise Edition (EE) i DataCleaner vi nu levere en enkelt sign-on option til skærmen ansøgningen. Nu DataCleaner kan være en integreret del af din it-infrastruktur, også sikkerhed-wise.
- ... Og meget mere:
- Ovenstående er blot et resumé. Mere end tredive problemer er blevet løst i denne udgivelse. Vi har løst flere anmodninger fra de fora og samfund, og vi opfordrer alle til at bruge dette medie som et middel til forandring. Vi er meget glade for at gøre udviklingen af DataCleaner være stærkt påvirket af de vandløb i samfundet.
Hvad er nyt i version 3.0.3:
- Tilføjer en service for at omdøbe job i overvågningen repository .
- Du kan få adgang til dette som en afslappende webtjeneste eller interaktivt i brugergrænsefladen.
- En webtjeneste blev tilføjet til at ændre den historiske dato for en analyse resultat i overvågningen repository.
- Web ansøgningen er forenelig med arven JSF containere.
- Caching af konfigurationen i Web ansøgning blev væsentligt forbedret, hvilket fører til hurtigere side belastning og job initialisering gange.
Hvad er nyt i version 3.0.2:
- Når udløser et job i overvågningen webapplikation, panelet automatisk opdateres hvert sekund for at få den seneste af fuldbyrdelsen.
- Fil-baserede datastores (såsom CSV eller Excel-regneark) med absolutte stier er nu korrekt løst i overvågningen webapplikation.
- & quot; Vælg fra nøgle / værdi map & quot; transformer understøtter nu indlejrede udvalgte udtryk som & quot; Address.Street & quot; eller & quot; ordrelinier [0] .product.name & quot;.
- tabelopslag mekanisme er blevet optimeret til ydeevne, ved hjælp forberedte udsagn, når du kører mod JDBC-databaser.
- Administratorer kan nu downloade filbaserede datastores direkte fra & quot; datastores & quot; side.
- Undtagelse håndtering i overvågningen webapplikation er blevet forbedret en smule, hvilket gør fejlmeddelelser mere præcis og intuitiv.
Hvad er nyt i version 3.0.1:
- Den primære bugfix i denne udgivelse var om at genoprette kortlægning af søjler og specifikke enumerable kategoriseringer. For eksempel i den nye Fuldstændighed analysator, fandt vi, at kortlægningen efter genindlæse en gemt job, ikke altid var korrekt.
- Derudover er der foretaget nogle interne forbedringer, hvilket gør det lettere at implementere DataCleaner monitor webapplikation i miljøer ved hjælp af Spring Framework.
- Sidst men ikke mindst, de visualisering indstillinger i desktop applikation er blevet forbedret med automatisk at tage et kig på det job, der visualiseres og toggling viste artefakter baseret på skærmstørrelse og mængden af detaljer, der er nødvendige for at vise det pænt.
Hvad er nyt i version 3.0:
- Visning af tidslinje og tendenser for datakvalitet målinger
- Centraliseret lager til håndtering og indeholder job, resultater, tidslinjer osv.
- Planlægning og revision af DataCleaner job
- Forudsat web services til at påberåbe DataCleaner transformationer
- Sikkerhed og multi-lejemål
- Advarsler og meddelelser når datakvalitet målinger er ude af deres forventede komfort zoner.
- Der er en ny fuldstændighed analysator, som er meget nyttigt for blot at identificere poster, der har ufuldstændige felter.
- Du kan nu eksportere DataCleaner resultaterne til pæn HTML rapporter, som du kan give til din leder, eller sende til din XML-parser!
- Den nye miljøovervågning også tæt integreret med desktop applikation. Således desktop applikation har nu mulighed for at offentliggøre job og resultater til skærmen repository, og der skal bruges som en interaktiv redaktør for indhold, der allerede i lageret.
- Nye dato-orienterede transformationer er nu tilgængelige: Dato interval filter, som giver dig mulighed for at delmængde datasæt baseret på datointervaller og format dato, som gør det muligt at formatere en dato ved hjælp af en dato maske .
- Regex Parser (som var tidligere kun tilgængelig via ExtensionSwap) er nu blevet inkluderet i DataCleaner. Dette gør det meget praktisk at parse og standardisere rige tekstfelter brug af regulære udtryk.
- Der er en ny tekst tilfælde transformer rådighed. Med denne transformation kan du nemt konvertere mellem store / små bogstaver og korrekt kapitalisering af sætninger og ord.
- To nye søg / erstat transformationer:. Plain søg / erstat og Regex søg / erstat
- Brugeroplevelsen af skrivebordet ansøgning er blevet forbedret. Vi har tilføjet flere i-ansøgning hjælp beskeder, gjorde farverne ser lysere og klarere og forbedret skrifttypen håndtering.
er blevet tilføjet
Hvad er nyt i version 2.5.2:
- Apache CouchDB support:
- Vi har tilføjet støtte til NoSQL-databasen Apache CouchDB. DataCleaner understøtter både læse fra, analysere og skrive til dine CouchDB instanser.
- Opdater tabel forfatter:
- Efter vores tidligere bestræbelser på at bringe ETLightweight-stil funktioner i DataCleaner, vi har tilføjet en forfatter, der opdaterer poster i en tabel. Du kan bruge dette for eksempel for at indsætte eller opdatere registreringer baseret på specifikke forhold.
- Ligesom Indsæt i tabellen forfatter, den nye DataCleaner Opdatering bord forfatter er ikke begrænset til SQL-baserede databaser, men enhver datalager type, der understøtter skriftligt (i øjeblikket relationelle databaser, CSV-filer, Excel-regneark, MongoDB databaser og MongoDB databaser), men semantik er de samme som med en traditionel UPDATE TABLE-sætning i SQL.
- Drill-til-detaljerede oplysninger gemt i resultat-filer:
- Når du bruger Gem resultat træk DataCleaner 2.5, nogle brugere har oplevet, at deres drill-til-detalje oplysninger blev tabt. I DataCleaner 2.5.2 vi nu også fortsætter denne information, hvilket gør dine DQ arkiver meget mere værdifuldt, når de efterforsker historiske data hændelser.
- Forbedret EasyDQ fejlhåndtering:
- De EasyDQ komponenter er blevet forbedret med hensyn til fejlhåndtering. Hvis en momentan netværk problem opstår eller anden lignende problem forårsager et par optegnelser til at mislykkes, vil EasyDQ komponenter nu yndefuldt komme sig og vigtigst -. Dit parti arbejde vil sejre, selv på trods af fejl
- Tabel kortlægning for NoSQL datastores:
- Da CouchDB og MongoDB ikke tabel baseret, men har en mere dynamisk struktur giver vi to tilgange til at arbejde med dem: Standard, som er at lade DataCleaner autodetektere en tabel struktur, og den avancerede som giver dig mulighed for manuelt at angive din ønskede tabel struktur. Tidligere den avancerede mulighed var kun tilgængelig via XML konfiguration, men nu indeholder brugergrænsefladen passende dialoger til at gøre dette direkte i programmet.
Hvad er nyt i version 2.4.1:
- Feature forbedringer:
- Batch lastning funktioner vi stærkt forbedret, når du skriver data til databasetabeller. Forvent at se mange størrelsesordener forbedringer her.
- Skrivning til data er blevet mere bekvemt stillet til rådighed ved at tilføje mulighederne til menuen vindue.
- Du kan nu nemt omdøbe komponenter i et job ved at dobbeltklikke på deres faner.
- Javascript transformer nu har syntaxfarvning, så dine Javascripts er lettere at inspicere og modificere.
- Fejlrettelser:
- Når læse fra og skrive til den samme datalager (f.eks. Den DataCleaner iscenesættelse område) vi har sørget for, at bordet cache af denne datalager opdateres. Tidligere nogle scenarier tilladt du se en out-of-date visning af tabellerne.
- En potentiel dødvande ved opstart ansøgningen blev løst. Denne fastlåste situation var en følge af et problem i JVM, men vi arbejdede omkring det ved at synkronisere alle opkald til den særlige API i Java.
Hvad er nyt i version 2.4: (. Aka Deduplikering eller Fuzzy matching af poster)
- Dubler afsløring , som er gratis at bruge for op til 500.000 værdier.
- Adresse datavalidering og udrensning. Dette giver dig mulighed for at kontrollere, om der findes adresser, hvis de er korrekt formateret og endda til at foreslå rettelser, hvis du har fejl.
- Navn datavalidering og udrensning. Med Navn service, betyder EasyDQ ikke kun formatere dine navne konsekvent, men kontrollerer også for stavefejl og fortolker navnet dele.
- e-mail og telefon validering og udrensning. Disse tjenester giver kontrol af e-mail og telefondata, og sørg for, at der findes e-mail-domæner, at landekoder er korrekte og meget mere.
Hvad er nyt i version 2.3:
- International data support:
- Hvis du arbejder med internationale data, så du kan have forskellige tegnsæt i dine data, for eksempel kinesisk eller hebraisk. Vi har tilføjet den Tegnsæt fordeling analysator, hvilket er en profilering indstilling, der lader dig finde ud af hvilket tegnsæt der bruges i dine data.
- Arbejde med data, der indeholder forskellige tegnsæt kan være problematisk. Brug den nye Transliterate transformer kan du nu omskrive strenge fra forskellige skriftsystemer til latinske bogstaver.
- Der er også en ny webcast demonstration, der fokuserer på de internationale data kapaciteter af DataCleaner 2.3 i dokumentationen afsnittet.
- Gruppering af analyseresultater af en sekundær kolonne:
- Mønster analysator er nu i stand til at gruppere mønstre baseret på en sekundær søjle. Dette er nyttigt for analyser som:
- Få mønstre af telefonnumre, grupperet efter land.
- Kom mønstre af e-mail-brugernavn baseret på e-mail domæne.
- Noget lignende er blevet gjort for Value Distribution analysator; dette giver mulighed for analyser som:
- Er alle bynavne tydelig, når grupperet efter postnummer?
- Hvad er fordelingen af køn inden for bestemte kundetyper?
- Forbedret diagrammer:
- Mønster Resultater af søgning De kan nu vises i et diagram. Dette gør fordelingen synlige og viser, hvor meget af en & quot; lang hale & quot; mønstre der er.
- Udgangen af værdien distributionen analysator er blevet forbedret i et par områder:
- læsbarhed af diagrammet er blevet forbedret.
- Den viser det totale antal rækker og adskilt tælle i disse rækker: antallet af forskellige værdier, der findes i rækkerne. Dette hjælper med at finde ud af, hvor ofte findes dublerede værdier.
- Hvis der er tomme strenge, bruger vi nøgleordet for det, så det er lettere at genkende dem.
- Output:
- Næste til de allerede eksisterende formater (CSV-filer og H2 datastores) vi tilføjet skrive output til Excel regneark.
- Efter at have skrevet til en datalager, er det nu muligt forpremiere output, så du kan kontrollere, om produktionen er i overensstemmelse med dine forventninger.
- Det er nu også muligt at tilføje output som en ny datalager, så den kan bruges som input til et nyt job.
- Andre forbedringer:
- Dokumentation er generelt blevet forbedret. Især har skovhugst og kommandolinje-interface beskrivelser blevet tilføjet.
- Forlængelsen mekanisme er blevet forbedret ved modularizing flere stykker ansøgningen og indføre Google Guice som et almindeligt tilgængelige afhængighed injektion rammer for udvidelse udviklere.
- Og selvfølgelig gjorde vi mere end tyve små forbedringer og fejlrettelser.
Hvad er nyt i version 2.2:
- Den vigtigste drivkraft for denne udgivelse har været en historie om udvidelsesmuligheder . Mens frigive ansøgningen vi samtidigt frigive en ny DataCleaner hjemmeside, som er udstyret med et vigtigt nyt område: ExtensionSwap. Ideen med ExtensionSwap er at tillade deling af udvidelser til DataCleaner og installation ved blot at klikke på en knap i browseren!
- DataCleaner extension API er blevet forbedret meget i denne udgivelse, hvilket gør det muligt at oprette dine egne transformere, analysatorer og filtre. Hvis du føler dine udvidelser kunne være af interesse for andre brugere, kan du dele det på ExtensionSwap og vi giver en kanal for dig nemt at distribuere det til tusindvis af brugere. Extension API og ExtensionSwap forklares yderligere i vores nye webcast demonstration for udviklere og andre teknikere med interesse.
- Vi er også frigive en række indledende udvidelser på ExtensionSwap: De HIquality Kontakter til DataCleaner forlængelse, som giver avanceret Navn, Telefon og e-mail-udrensning, baseret på menneskelige følgeslutninger naturligt sprog forarbejdning DQ web services. Vi er også shipping en prøve forlængelse, som vil tjene som et eksempel for udviklere, der ønsker at prøve extension udvikling selv. I de kommende måneder vil vi sørge for at skrive endnu flere udvidelser stammer fra vores interne portefølje af værktøjer, som vi bruger på menneskelige Inference s videnindsamling teams.
- Udover udvidelsesmuligheder vi også fokus på embeddability. Vi ønsker at være i stand til at integrere DataCleaner let i andre programmer til at gøre profilering og dataanalyse mulig overalt! Vi har oprettet en ny bootstrapping API, der gør det muligt for programmer at bundte DataCleaner og bootstrap det med en dynamisk konfiguration eller køre det i en & quot; single datalager tilstand & quot ;, hvor ansøgningen er tunet mod blot at inspicere et enkelt datalager (typisk defineret af ansøgningen der integrerer DataCleaner). Vi har allerede nogle virkelig interessante tilfælde af indlejring DataCleaner i værker -. Både i andre open source-programmer samt kommercielle applikationer
- Vi har tilføjet understøttelse til analyse SAS datasæt. Det er noget, vi er ret stolte af, som vi er, så vidt vi ved, at den første store open source program giver en sådan funktionalitet, i sidste ende befriende en masse SAS brugere. SAS interoperabilitet del blev oprettet som et særskilt projekt, SassyReader, så vi forventer at se vedtagelse i DataCleaner s gratis open source fællesskaber snart også!
- Vi har også tilføjet understøttelse af en anden type datalagerenheder: Fast bredde filer. Fast bredde filer er tekstfiler, hvor hver kolonne har en fast bredde. Der er ingen separator eller citat karakter, ligesom CSV-filer, i stedet hver linje er lige lange, og hver linje vil blive tokenized efter et sæt af value længder.
- En mulighed til & quot; mislykkes på uoverensstemmelser & quot; blev sat til CSV-fil og fast bredde fil datastores. Disse flag tilføje et format integritet kontrol når du bruger disse tekstfil baserede datastores.
- En fejl blev rettet, som forårsagede CSV separator indstillingerne ikke at blive tilbageholdt i brugergrænsefladen, når du redigerer en CSV datalager.
- japanske og andre tegn understøttes ikke i brugergrænsefladen. Dette & quot; bug & quot; var et spørgsmål om at undersøge tilgængelige skrifttyper på systemet og vælge en skrifttype, der kan gengive de særlige tegn. På de fleste moderne systemer vil der være stand skrifttyper til rådighed, men på nogle Unix / Linux grene der kan stadig være begrænsninger.
- Dokumentationen sektionen er blevet opdateret! Lige siden den første 2.0 release dokumentationen har været langt bagefter, men vi har endelig lykkedes at få den opdateret. Der er stadig stykker mangler i docs, men det burde definitivt være nyttigt for grundlæggende brug samt en reference for de fleste emner.
- Application opstartstid blev forbedret ved parallelizing konfigurationen lastning og ved at forsinke initialiseringen af de dele af den konfiguration, der ikke er nødvendige for den indledende vindue display.
- fonetiske lighed Finder analysator er blevet fjernet fra de vigtigste fordeling, da dette var ganske eksperimenterende og tjener mest som en proof of concept og en appetitvækker til samfundet for at skabe mere avancerede matchende analysatorer. Du kan nu finde og installere den fonetiske lighed finderen på ExtensionSwap.
- Annulleret eller errornous job håndtering blev forbedret og brugerfladen reagerer mere korrekt ved at deaktivere knapper og indikatorer for fremskridt, hvis et job er stoppet.
- Fast nogle mindre UI spørgsmål vedrørende bord dimensionering og brug af scrollbars.
Hvad er nyt i version 2.1.1:
- Forbedringer:
- Tilføjet en søgning / filtrering tekstfeltet på listen datastores. Dette giver dig mulighed for hurtigt at finde din datalager, hvis du har registreret flere datastores end tilgængelige på skærmen.
- Referencedata for landekoder blev sat til den standard distribution, tak går til Graham Rhind for at levere disse.
- Tilføjet en vandret rullepanel til data forhåndsvisning vinduer i der er mere end 10 kolonner.
- Mulighed for at tilføje en udvidelse pakke med ny funktionalitet i dialogboksen Indstillinger på runtime. Mere fokus på udvidelser vil følge i de kommende udgivelser.
- Vi har udsat en tidlig preview af vores Command Line Interface (CLI) ved at tillade dig at påberåbe programmet med & quot; -Brug & quot; parameter, som vil vise CLI muligheder.
- Tilføjet talformatering muligheder til & quot; Konverter til nummer & quot; transformer.
- Fejlrettelser:
- Rettet en out-of-memory problem, når forespørge borde med en masse kolonner (150 +).
- Fixed et problem, der forårsager den & quot; Limit analyse & quot; afkrydsningsfeltet for ikke kontrolleres korrekt, når et job blev genåbnet efter lagring.
- Egentlig ikke en fejlrettelse som det var aldrig en officiel funktion, men nu understøtter vi genskabe brugerindstillinger (den userpreferences.dat fil) fra tidligere versioner af DataCleaner.
Hvad er nyt i version 2.1:
- Der var en masse arbejde på brugergrænsefladen ( se medier side):
- Vi besluttede at fjerne den venstre siderude indeholder konfigurations miljø muligheder.
- I stedet alle disse muligheder er nu blevet flyttet til jobbet bygning vindue, så brugeren kun skal fokusere på et enkelt vindue for alle interaktioner er nødvendige for at udforme en opgave.
- Dialogen velkommen / login er også blevet fjernet til fordel for et mere diskret panel, der kan trækkes i eller skjult fra hovedvinduet.
Kommentarer ikke fundet