
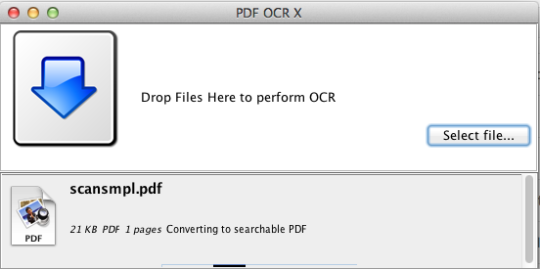
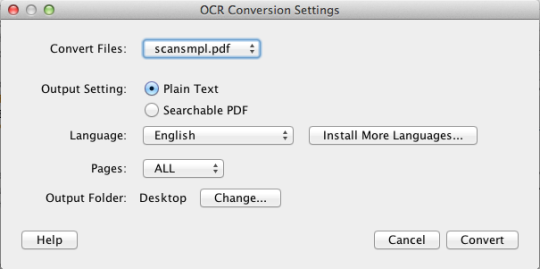
PDF OCR X er et enkelt træk og slip-værktøj til Mac OS X, der konverterer dine PDF-filer og billeder til tekst eller søgbare PDF-dokumenter. Den bruger avanceret OCR-teknologi (optisk tegngennkendelse) til at udtrække teksten i PDF-filen (eller billedet), selvom teksten er indeholdt i et billede. Dette er især nyttigt til håndtering af PDF-filer og billeder, der blev oprettet via en Scan-to-PDF-funktion i en scanner eller fotokopier. Støtter over 60 sprog til OCR. OCR-motoren er baseret på Tesseract. EF-udgaven understøtter enkeltside PDF-filer (eller den første side i PDF-sider med flere sider). For multi-siders PDF-support skal du opgradere til Enterprise Edition.
Hvad er nyt i denne udgave:
Version 2.1.1 tilføjer support til Mojave , og forbedrer brugergrænsefladen på nethinden.
Hvad er nyt i version 2.0.8:
Fast problem med håndtering af nogle PDF-filer med rotation.
Begrænsninger :
Gemenskapsudgaven er begrænset til enkeltsidede PDF-filer og billeder.


Kommentarer ikke fundet