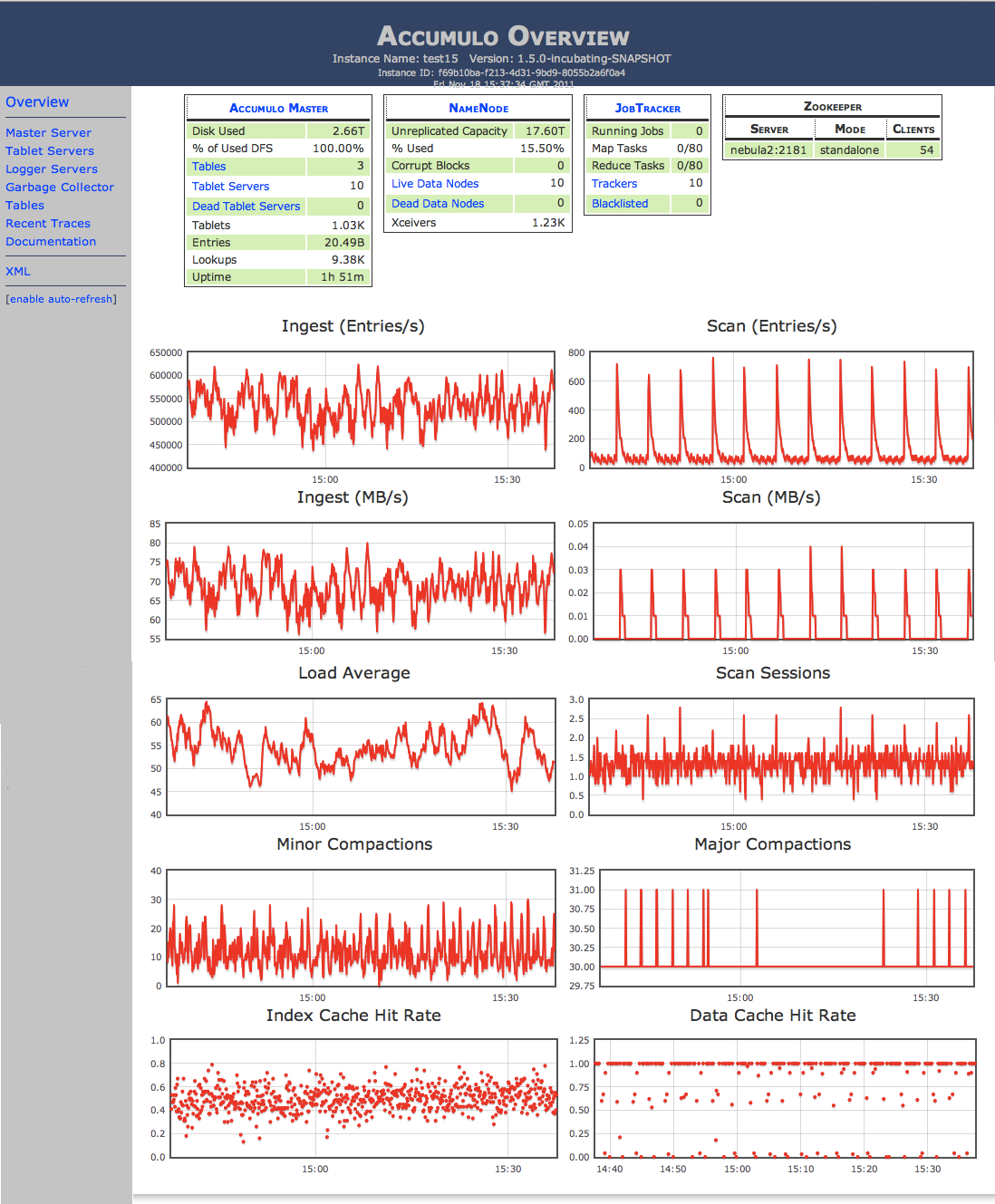
Apache Accumulo er en mashup af forskellige teknologier, fra Googles BigTable , til Apache Hadoop , Thrift og Zookeeper .
I forhold til Googles BigTable system Accumulo byder et par forbedringer af sine egne.
Disse omfatter table cellebaserede adgangsbegrænsninger, en server-side-system til styring af nøgleværdipar ved ønskede tidspunkter og under optimale forhold, og masser af klient-API'er.
Databasen er bestemt ikke til at køre din hver dag hjemmesider og er målrettet til cloud-computing miljøer, hvor udviklerne har brug for at håndtere humongous mængder af information
Hvad er nyt i denne udgivelse.:
- Anvendelse af Hadoop CredentialProviders
- Write-Ahead Log sync ydeevne
- Minor-komprimeringsmaskine ikke aggressiv nok
- Write-Ahead log sync implementering
- HeapIterator optimering
Hvad er nyt i version 1.6.2:
- Anvendelse af Hadoop CredentialProviders
- Write-Ahead Log sync ydeevne
- Minor-komprimeringsmaskine ikke aggressiv nok
- Write-Ahead log sync implementering
- HeapIterator optimering
Hvad er nyt i version 1.6.0:
- service IP-adresser
- Multiple volumen support
- Tabel navnerum
- Pluggable komprimering strategier
- Betingede mutationer
- Lokalitet grupper i hukommelsen
- Størrelse baseret begrænsning på nye tabeller
Hvad er nyt i version 1.4.1:.
- Valgfrit overvåge Swappiness på hver server
- Support kører på toppen af Kerberos-aktiverede HDFS.
- Give metode til indsamling af systemets statistik til API.
Hvad er nyt i version 1.4.0:
- Tablet sammenlægning
- Effektiv sletning af rækken interval
- Komprimering af rækken interval
- Tabel kloning
- SKÆBNE: Fejl Tolerant Executor. Bruges til at gøre tabellen operation overlever mester genstart.
- Samtidig tabel drift udføre korrekt
- Bulk belastning er nu udført af master-og tablet-servere og bruger SKÆBNE at overleve serveren genstartes.
- Multi-level RFIL indeks
- Sammenlægning mindre komprimeringsmaskine
- Logisk tid for bulk import
Kommentarer ikke fundet